
In the last couple of posts, I considered whether the Frobenius distance/norm or Pearson correlation coefficient were appropriate ways to compare my 4 POS transition matrices. Also, I have produced similarity matrices and scatter plots as more visual ways of trying to garner anything useful – I think the scatter GIFs are probably the most effective. For the similarity matrices one, if one the authors’ matrices is 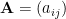 and the other is
and the other is  I just form the similarity matrix as
I just form the similarity matrix as  . No rocket science (or early 20th-century eugenics inspired statistics in the case of the Pearson coefficient. Then I produced heat maps of
. No rocket science (or early 20th-century eugenics inspired statistics in the case of the Pearson coefficient. Then I produced heat maps of  . I further modified the code for the HeatChart java library to make it a bit more visual, with blue as negative, white as zero-difference, and red as positive.
. I further modified the code for the HeatChart java library to make it a bit more visual, with blue as negative, white as zero-difference, and red as positive.
The Results [Queue FANFARE…We got there!]
Now that I have gone through the different ways I am trying to compare my 4 matrices (phew!) here are the outputs:
Frobenius and Pearson
[table id=pearson_frob /]
The first value in the table is the Pearson correlation coefficient, 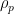 : ‘1’ would be a perfect positive correlation. The second value is the Frobenius distance derived using the Frobenius norm: ‘0’ would be no distance.
: ‘1’ would be a perfect positive correlation. The second value is the Frobenius distance derived using the Frobenius norm: ‘0’ would be no distance.

It is nice to know, give or take, that the two,  and
and  pretty much give the same conclusion. I am sure if you did the algebra on Pearson Correlation vs Frobenius distance you could see why the differences come from more quantitively.
pretty much give the same conclusion. I am sure if you did the algebra on Pearson Correlation vs Frobenius distance you could see why the differences come from more quantitively.
Animated Scatter Plots
Not sure what you do with these other than look at them at try and decide which plot in each of the four animations is nearest to being a straight line…a perfect line would give you a Pearson Correlation of 1. Taking the animations from ‘left/top’ to ‘right/bottom’ they show:
- My data vs the remaining others
- Hemingway vs the remaining others,
- Darwin vs the remaining others and;
- Baum vs rest.
The only thing I can really draw from them is they are all pretty different! Maybe Hemingway vs Baum is the “I’m nearest a line” winner?




BTW, I draw the scatter plots using a great little one-class library I found called Simple Plot: it does what it says on the packet, if think you’d agree?
Heat Maps
In these, a blue cell means a negative difference between the first author in the chart title and the second. A red cell is a positive difference. White is zero difference. So for Mine vs Darwin, if its blue then I do it way more than him.
Here I am using the Wordpress ‘Slide Anything’ carousel plugin BTW.
[slide-anything id=”1134″]